转载自 https://mp.weixin.qq.com/s/O1lKrO3zl0hA-mlb79gw7Q
既然使用消息中间件就一定涉及到一个重要问题,如何保证消息不丢失?使用Kafka也不例外。
简单来说,一条消息会经历如下三个位置的流转:生产者、服务端、消费者。那么如何保证消息不丢失也要从三个角度来考虑:生产者发送消息、服务端存储消息、消费者消费消息。
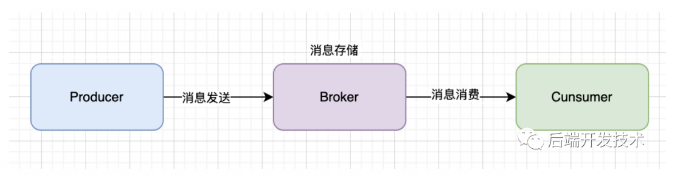
Kafka并不是一个神乎其神的智能框架,它不丢失消息的前提是在这三个环节都正确,要求我们正确使用、正确配置。
发送消息角度
使用有callback的send方法
发送消息要使用正确方法。
Kafka 是异步发送消息的,也就是说我们调用 send 方法后立即拿到了结果,并不代表这条消息一定是发送成功的。如果使用的是producer.send(msg)方法,就是这样的效果。这时候你有可能会发现方法明明调用成,但是Broker里却并没有收到这条消息。
你可能会说,那把异步改成同步不就好了。因为send调用后会拿到一个feature对象,直接调用 get方法便会同步阻塞等待结果。要么消息发送成功,要么发送失败抛出异常,根据异常做出相应的处理,比如回滚、补偿。但是阻塞等待结果会严重影响性能,一般并不适用。
producer.send(record).get();
那么应该如何保证发送的消息一定被broker收到又要保证效率呢?
需要使用有回调(callback)的send 方法:
producer.send(msg, callback)。kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null){ System.out.println("主题:"+metadata.topic() + " 分区:"+ metadata.partition()); } }});
它依旧是采用异步发送,所以消息发送的吞吐量并不受影响。采用回调函数的方式来获得消息发送的最终结果,最终是失败还是成功,提高了消息发送的可靠性。
它能准确地告诉你消息是否真的提交成功了。一旦出现消息提交失败的情况,你就可以有针对性地进行处理。
举例来说,如果是因为那些瞬时错误,那么仅仅让 Producer 重试就可以了;如果是消息不合格造成的,那么可以调整消息格式后再次发送。总之,处理发送失败的责任在 Producer 端而非 Broker 端。
异步发送,采用了callback的方式来回调,提高了消息发送的吞吐量,也一定程度的提高了消息的可靠性,根据回调的结果来判断是否需要做相应的回滚逻辑。
配置 ack=all
producer提供了三种消息确认的模式,通过配置acks来实现
acks=1时(默认),表示数据发送到Kafka后,经过leader成功接收消息的的确认,才算发送成功,如果leader宕机了,就会丢失数据。
acks=0时, 表示生产者将数据发送出去就不管了,不等待任何返回。这种情况下数据传输效率最高,但是数据可靠性最低,当 server挂掉的时候就会丢数据;
acks=-1/all时,表示生产者需要等待ISR中的所有follower都确认接收到数据后才算发送完成,这样数据不会丢失,因此可靠性最高,性能最低。
将ack参数配置为 all,表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”,这样可靠性最高。
设置发送重试 retries和max.in.flight.requests.per.connection
当发送失败时,比如网络抖动的原因,客户端会进行重试,重试的次数由retries指定。此参数默认设置为0,即:快速失败模式当发送失败时由客户端来处理后续是否要进行继续发送。如果设置 "retries> 0 而没有设置max.in.flight.requests.per.connection=1 "则意味着放弃发送消息的顺序性。retries = 3max.in.flight.requests.per.connection = 1
这样设置后,发送客户端会最大重试3次,直到broker返回ack。同时只有一个连接向broker发送数据,保证了数据的顺序性。
Broker 角度
设置 replication.factor >= 3
该参数表示分区副本的个数(之前已经介绍过了副本的概念)。replication.factor =3
建议设置大于1,至少有一个副本,随着业务的重要性提升可以增加副本数量。如果 Leader 副本出现不可用,Follower 副本会被选举为新的 Leader 副本继续提供服务。冗余存储数据,做备份本身就是一种提升消息可靠性的办法。
设置 unclean.leader.election.enable = false
该参数表示有哪些 Follower 可以有资格被选举为 Leader 。unclean.leader.election.enable = false
如果一个 Follower 的数据落后 Leader 太多,那么一旦它被选举为新的 Leader, 数据就会丢失,因此我们要将其设置为false,防止此类情况发生。
设置 min.insync.replicas > 1
该参数表示消息至少要被写入成功到 ISR 多少个副本才算"已提交",默认值是1,建议设置 min.insync.replicas > 1,这样才可以提升消息持久性,保证数据不丢失。min.insync.replicas = 2
另外我们还需要确保一下replication.factor > min.insync.replicas,如果相等,只要有一个副本不可以,整个 partition 将无法正常提供服务。
为了保证消息持久性的同时还要保证可用性,推荐设置成:replication.factor =min.insync.replicas +1, 最大限度保证系统可用性。
消费消息角度
消息处理完成后再提交
首先要明白,consumer消费消息的时候是用 消费者位移(Consumer Offset) 来标记消费位置的。之前的文章已经提及过。
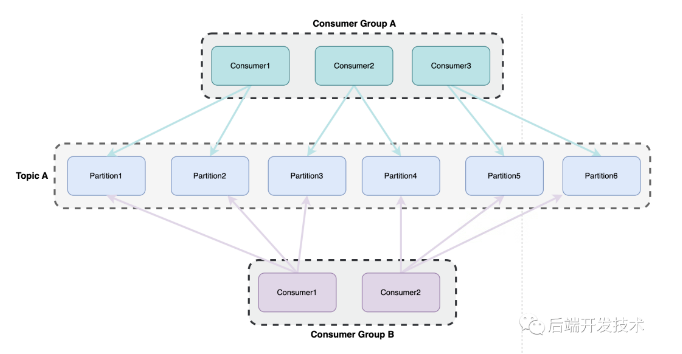
一个partition可以被多个消费者组的不同消费者消费,并且分别记录其位移数据,如下图。
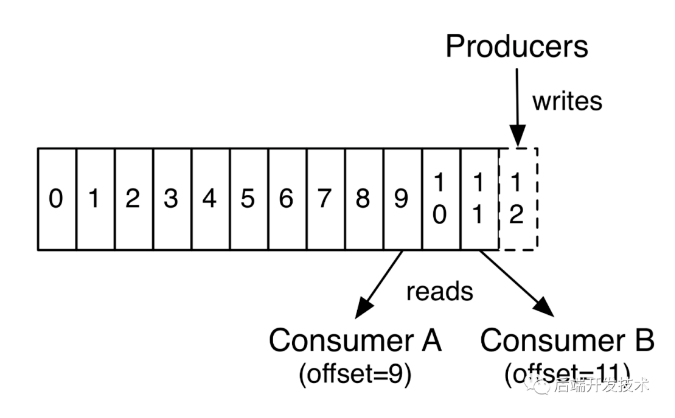
每次接收到消息并处理完业务逻辑消费完成后,我们要明确的告诉客户端消费的位移。注意是先消费然后更新位移。我们还需要设置参数enable.auto.commit = false, 采用手动提交位移的方式。
如果先更新位移,然后再异步消费会导致如果业务逻辑失败,但是位移已经更新成功,相当于这条失败的消息以后无法处理。
注意如果是系统预期外的异常,不要catch住,这样也会导致消费失败后无法重试。
谨慎使用批量消费,推荐单条拉取
Kafka 消费者都是采用主动拉取的方式来从 broker 获得消息的,如果是批量消费,比如一次消费10条数据,需要在失败的消息处准确的返回消息位移。比如处理第5条消息处理失败,那就需要返回位移 5,下次拉取消息重新从这条开始消费。
如果是多线程处理消费,那么位移就更不好处理了,比如来2个线程,每个线程处理5条,A处理成功2条,B处理3条,位移该如何返回?
推荐使用单条消息拉取的模式,这样异常处理和位移处理都最方便,也没有并发的问题,性能上的影响一般都可以接受。
额外提一句,消息的处理都要注意幂等性,无论是位移导致的重新消费,还是在Kafka rebalance时候导致的重新消费,都需要我们注意这个问题。