线程状态

wait()和sleep()
最大区别,wait()会释放锁,在被唤醒后再申请锁,而sleep若是在synchronized中,不会释放锁
-
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会;
-
sleep()是Thread类的Static(静态)的方法;因此他不能改变对象的机锁,所以当在一个Synchronized块中调用Sleep()方法是,线程虽然休眠了,但是对象的机锁并木有被释放,其他线程无法访问这个对象(即使睡着也持有对象锁)。
-
在sleep()休眠时间期满后,该线程不一定会立即执行,这是因为其它线程可能正在运行而且没有被调度为放弃执行,除非此线程具有更高的优先级。
-
wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);其他线程可以访问;
-
wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。
-
wiat()必须放在synchronized中,否则会在program runtime时扔出”java.lang.IllegalMonitorStateException“异常。
join()
使当前线程阻塞,等调用join的线程执行完后才能执行。
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}//循环判断子线程是否存活,存活则一直等待
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
源码可以看出,主线程会循环判断子线程是否存活,存活则一直等待。这里的wait()是当前运行的线程,即主线程。
实现方式
- 继承自Thread类(不能线程共享)
- 实现Runnable接口(无返回值),用线程池的execute或submit提交
- 实现Callable接口(有返回值,可能抛出异常),用线程池的submit提交,常用Future获取异步结果
Runnable和Thread的区别
- Runnable是接口,定义了一个抽象的run()方法。这个方法会在线程执行时被调用。
- Thread是类,实现了Runnable接口。类只能单继承,如果要继承其他类就需要自己实现Runnable接口。
- 启动线程必须要通过start()方法(调用的native非java代码),因此如果实现了Runable接口的可以构造Thread,而不能通过run(),否则只是调用了一个普通方法而已。
- 如果用一个Runnable对象构造了多个线程,多个线程都start()起来,Runnable对象的属性都是共享的,相当于多个线程共同做一件事。
Callable接口和Future接口
public interface Callable<V> {
V call() throws Exception;//返回值就是传入的泛型参数
}
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);//参数表示是否取消正在运行的线程,返回值表示是否取消成功;如果线程还没有执行,总是返回false
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
eg.
class Task implements Callable<Integer>{...}
...
Future<Integer> result = executor.submit(task);
result.get()
FutureTask
实现RunableFuture接口(顾名思义,既可以作为线程运行又可以获取结果)
class Task implements Callable<Integer>{...}
...
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
futureTask.get();
Future模式
Future模式是多线程开发中非常常见的一种设计模式。它的核心思想是异步调用。
//返回客户端的立即凭据
public class FutureData<T> {
Object data;//处理结果
boolean isReady;//是否处理完毕标志
//由处理线程处理完写入
public synchronized void setData(Object data){
this.data=data;
isReady=true;
notifyAll();
}
//由客户端通过凭据获取
public synchronized Object getData(){
while (!isReady){
try{
wait();
}catch (Exception e){
}
}
return data;
}
}
//服务端
public class Server {
final FutureData<String> returnFirst=new FutureData<>();
public FutureData<String> handleReq(){
//创建一个线程处理请求,就返回凭据
new Thread(new Runnable(){
@Override
public void run() {
try {
Thread.sleep(2000);
}catch (Exception e){}
returnFirst.setData("绝密文件");
}
}).start();
return returnFirst;
}
}
//调用
Server server=new Server();
FutureData<String> returnData=server.handleReq();
String doElse=" ";//做其他的事情
System.out.println(returnData.getData());
线程池
优点:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会无限循环获取工作队列里的任务来执行。 - 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。
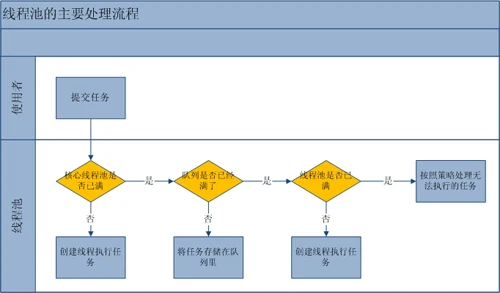
创建
- Executors的静态方法,返回ExecutorService实例;
- newCachedThreadPool():线程数无限制;有空闲线程则复用空闲线程,若无空闲线程则新建线程;一定程序减少频繁创建/销毁线程,减少系统开销.
- newFixedThreadPool():可控制线程最大并发数(同时执行的线程数);超出的线程会在队列中等待
- newScheduledThreadPool():支持定时及周期性任务执行。
- newSingleThreadExecutor():有且仅有一个工作线程执行任务;所有任务按照指定顺序执行,即遵循队列的入队出队规则
- new ThreadPoolExecutor(xxxx),返回ThreadPoolExecutor实例(继承自AbstractExecutorService);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {...}
- corePoolSize和maximumPoolSize定义了进入队列和执行饱和策略的线程数阕值
- keepAliveTime线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
- ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字,便于排查问题。
- RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。
AbortPolicy(默认):直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
配置
- 任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
- 任务的优先级:高,中和低。
- 任务的执行时间:长,中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能小的线程,如配置Ncpu+1个线程的线程池。IO密集型任务则由于线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
(节选自http://www.infoq.com/cn/articles/java-threadPool)
启动/提交
- execute(Runnable one) ,无返回值
- submit(Runnable or Callable
),有返回值
get方法会阻塞住直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞一段时间后立即返回,这时有可能任务没有执行完。
Future<Object> future = executor.submit(harReturnValuetask);
try {
Object s = future.get();
} catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池
executor.shutdown();
}
关闭
- 调用线程池的shutdown或shutdownNow方法
- 原理都是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。
- shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
- 调用了两者中任何一个关闭方法,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法才会返回true。
- 通常调用shutdown来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow。
监控
- 线程池参数
taskCount:线程池需要执行的任务数量。
completedTaskCount:线程池在运行过程中已完成的任务数量。小于或等于taskCount。
largestPoolSize:线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过。如等于线程池的最大大小,则表示线程池曾经满了。
getPoolSize:线程池的线程数量。如果线程池不销毁的话,池里的线程不会自动销毁,所以这个大小只增不减 getActiveCount:获取活动的线程数。
public class MonitorThread implements Runnable {
ExecutorService executorService;
boolean run;
public MonitorThread(ExecutorService executorService) {
this.executorService = executorService;
this.run=true;
}
public void shutdown(){
this.run=false;
}
@Override
public void run() {
ThreadPoolExecutor executor=(ThreadPoolExecutor)executorService;
while(run){
System.out.println(
String.format("[monitor] [%d/%d] Active: %d, Completed: %d, Task: %d, isShutdown: %s, isTerminated: %s",
executor.getPoolSize(),//当前线程数量
executor.getCorePoolSize(),//基本线程数量
executor.getActiveCount(),//活动线程数
executor.getCompletedTaskCount(),//已完成任务数
executor.getTaskCount(),//需要执行的任务数
executor.isShutdown(),//是否已调用关闭方法
executor.isTerminated()));//是否已关闭
try {
Thread.sleep(1*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
- 实现方法
通过继承线程池并重写线程池的beforeExecute,afterExecute和terminated方法,我们可以在任务执行前,执行后和线程池关闭前干一些事情。如监控任务的平均执行时间,最大执行时间和最小执行时间等。
线程同步的方法
同步是一种高开销的操作,因此应该尽量减少同步的内容。
临界区(critical section):不管是同步代码块还是同步方法,每次只有一个线程可以进入,如果其他线程试图进入(不管是同一同步块还是不同的同步块),JVM会将它们挂起(放入到等锁池中)。
- synchronized
- volatile
用在变量上,不能用在final类型的变量,变量的值在使用之前总会从主内存中再读取出来。对变量值的修改总会在完成之后写回到主内存中。保证数据可见性,不提供原子操作。 - 可重入锁ReentrantLock
- 使用局部变量 ThreadLocal,每个线程都有自己的副本
new ThreadLocal(T) : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
- 阻塞队列LinkedBlockingQueue,公用一个队列
LinkedBlockingQueue() : 创建一个容量为Integer.MAX_VALUE的LinkedBlockingQueue
put(E e) : 在队尾添加一个元素,如果队列满则阻塞
size() : 返回队列中的元素个数
take() : 移除并返回队头元素,如果队列空则阻塞
- 使用原子型变量,如AtomicInteger(util.concurrent.atomic)
synchronized
- synchronized可以用在方法或者代码块(颗粒更细一点)上
如果是synchronized(this){},那么其他线程执行到同个对象的这段代码,必须要等持有对象锁的线程执行完才有机会;如果要锁住代码要通过synchronized(类名.class){},这样如果就算是不同对象执行到这边也是要等待锁的 - 只能锁定对象,不能锁定基本数据类型
- 被锁定的对象数组中的单个对象不会被锁定
- 静态同步方法会锁定它的Class对象
- 内部类的同步是独立于外部类的
- synchronized修饰符并不是方法签名的组成部分,所以不能出现在接口的方法声明中
- 线程要么得到锁,要么阻塞,没有其他的可能性
- synchronized实现的锁是可重入的锁。
可重入锁ReentrantLock
是可重入、互斥、实现了Lock接口的锁
常用方法
- ReentrantLock() : 创建一个ReentrantLock实例
- lock() : 获得锁
- unlock() : 释放锁
class Bank {
private int account = 100;
//创建锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
public void save(int money) {
lock.lock();//加锁
try{
account += money;
}finally{
lock.unlock();//解锁
}
}
}
并发集合类
Java 5以后出现的并发集合类就是专门针对普通集合出现不能并发和不能在迭代过程中修改数据等问题而出现的。
主要有:
- ConcurrentHashMap(替代hashtable);
- ConcurrentSkipListMap;
- ConCurrentSkipListSet;
- CopyOnWriteArrayList
(是ArrayList 的一个线程安全的变形,其中所有可变操作(添加、设置,等等)都是通过对基础数组进行一次新的复制来实现的。这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更 有效;自创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。不支持迭代器上更改元素的操作(移除、设置和添加)。); - CopyOnWriteArraySet;
- ConcurrentLinkedQueue
- (此队列按照 FIFO原则对元素进行排序,队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。不允许 null 元素。 )
其他
- 数据副本是避免共享数据的好方法,复制出来的对象只是以只读的方式对待(写时复制,如CopyOnWriteArrayList)
- Servlet就是以单实例多线程的方式工作,和每个请求相关的数据都是通过Servlet子类的service方法(或者是doGet或doPost方法)的参数传入的。只要Servlet中的代码只使用局部变量,Servlet就不会导致同步问题。Spring MVC的控制器也是这么做的,从请求中获得的对象都是以方法的参数传入而不是作为类的成员,很明显Struts 2的做法就正好相反,因此Struts 2中作为控制器的Action类都是每个请求对应一个实例